Recap:
Project: Translation Project
14 Transfer learning
In this lesson, you’ll be using one of these pretrained networks, VGGNet, to classify images of flowers.
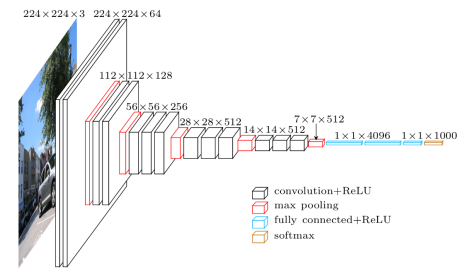
VGG (Visual Geometry Group), is an Oxford team led by Andrew Zisserman and Andrea Vedaldi. In VGGNet, only 3x3 convolution and 2x2 pooling are used throughout the whole network. It is quite famous because not only it works well, but the Oxford team have made the structure and the weights of the trained network freely available online. The Caffe weights are directly downloadable on the project’s web page; there are converted versions for other frameworks available around if you google them. One drawback of VGGNet is that this network is usually big. It contains around 160M parameters. Most of the parameters are consumed in the fc layers.
setup
git clone https://github.com/udacity/deep-learning.git
20170401
cd 20170401/transfer-learning
git clone https://github.com/machrisaa/tensorflow-vgg.git tensorflow_vgg
source activate py3
pip install tqdm
conda install scikit-image
“Transfer_Learning.ipynb” relies on
tensorflow_vgg. Running the first code cell will download the parameter file (vgg16.npy, 553MB, ) from aws to the tensorflow_vgg folder.
This notebook is converted from the TensorFlow inception tutorial and shared the same dataset (flow_photos.tar.gz, 229MB). There are five classes: daisy (634 jpg files), dandelion (899), roses(642), sunflowers(700), tulips (800). A total of 3670 instances.
The complete VGGNet is 5 conv layers + 2 dense layers. Here, we only use the output of first 5 conv layers as a feature extractor. the input images have shape (244,244,3).
vgg16.Vgg16().relu6 acts as a superpower image preprocessing machine that crush each image into fundamental pieces that are “really” ready for efficient classification. What exactly are these fundamental pieces? Maybe dots, lines, shapes, etc, we are not sure yet.
Supress warning by
import warningswarnings.filterwarnings("ignore") After my 2013 macbook painstakingly spinning for 6785s, I get these exciting pieces named as “codes“(60 MB). Each image or code is a vector with 4096 dimensions.
Then use a simple neural network with a 256-node layer to build a classifier. Train it and store it. Then randomly pick a flower image and let the fortune teller do the magic!
There are several tricks in
vgg16.py to expedite the model building. The pre-trained parameter from vgg16.npy is loaded into Vgg16().data_dict during the class initialization and reset to None after building. It is computational expensive because of the many layers and huge number of parameters.
The filter size is stored by the name of the target layer. Each layer actually has multiple filters.

15 Sequence to Sequence
Instructor: Jay Alammar
Sequence to Sequence, published in 2014 by https://arxiv.org/abs/1409.3215, is one of RNN architectures that maps many to many.
One of the authors, Quoc Le, gave a talk: https://github.com/ematvey/tensorflow-seq2seq-tutorials
Chatbot dataset: Cornel Movie Dialogs Corpus, 200 k conversations from 600 movie scripts.
sequence to sequence tutorial: https://github.com/ematvey/tensorflow-seq2seq-tutorials
16 Deep Q learning
use neural networks to replace the Q-table.
gym
Project: language translation
It’s all about getting familiar with the RNN architectures using Tensorflow. The codes are almost identical to Course 15: seq2seq.