1 GAN
Instructor: Ian Goodfellow
stackgan model: takes a textual description, then generate photos matching the description. GAN draws a sample from the probability distribution over all hypothetical images matching that description.
iGan, developed by Berkeley and Adobe.
cat, cartoon, image translation, simulation. Most of the applications of GANs have probably not invented yet.
how GANs work? Game theory between counterfeit maker and police. The generator and the discriminator are in a competition with each other. Saddle point is where equilibrium achieves.
4 Hyperparameters
Yoshua Bengio: Learning rate is the single most important hyper parameter and one should always make sure that has been tuned.
Good start point: 0.01
Exponential Decay in TensorFlow.
minibatch is something between online(stochastic) training and batch training.
32 to 256 is good candidates. too small will train too slow, too large will require more memory.
number of iteration. A technique is called early stopping. TensorFlow provides SessionRunHooks (previously was ValidationMonitor)
number of hidden layers. The 1st hidden layer usually has larger number of nodes than input. 3 hidden units are typically good enough unless CNN is used.
RNN architecture: vanilla RNN cell, LSTM cell, GRU (Gated recurrent unit) cell. Their comparison is still in hot debate. Typical embedding size are 50-200.
more about hyperparameter:
- Practical recommendations for gradient-based training of deep architectures by Yoshua Bengio
- Deep Learning book - Chapter 11.4: Selecting Hyperparameters by Ian Goodfellow, Yoshua Bengio, Aaron Courville
- Neural Networks and Deep Learning book - Chapter 3: How to choose a neural network’s hyper-parameters? by Michael Nielsen
- Efficient BackProp (pdf) by Yann LeCun
More specialized sources:
- How to Generate a Good Word Embedding? by Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao
- Systematic evaluation of CNN advances on the ImageNet by Dmytro Mishkin, Nikolay Sergievskiy, Jiri Matas
- Visualizing and Understanding Recurrent Networks by Andrej Karpathy, Justin Johnson, Li Fei-Fei
projects
- gan_mnist
- dcgan_svhn
- face-generation
- semi_supervised
notes:
A simplified model description is as below:

However, it is somewhat misleading. The tensorboard is better at articulate the complicated relationship:
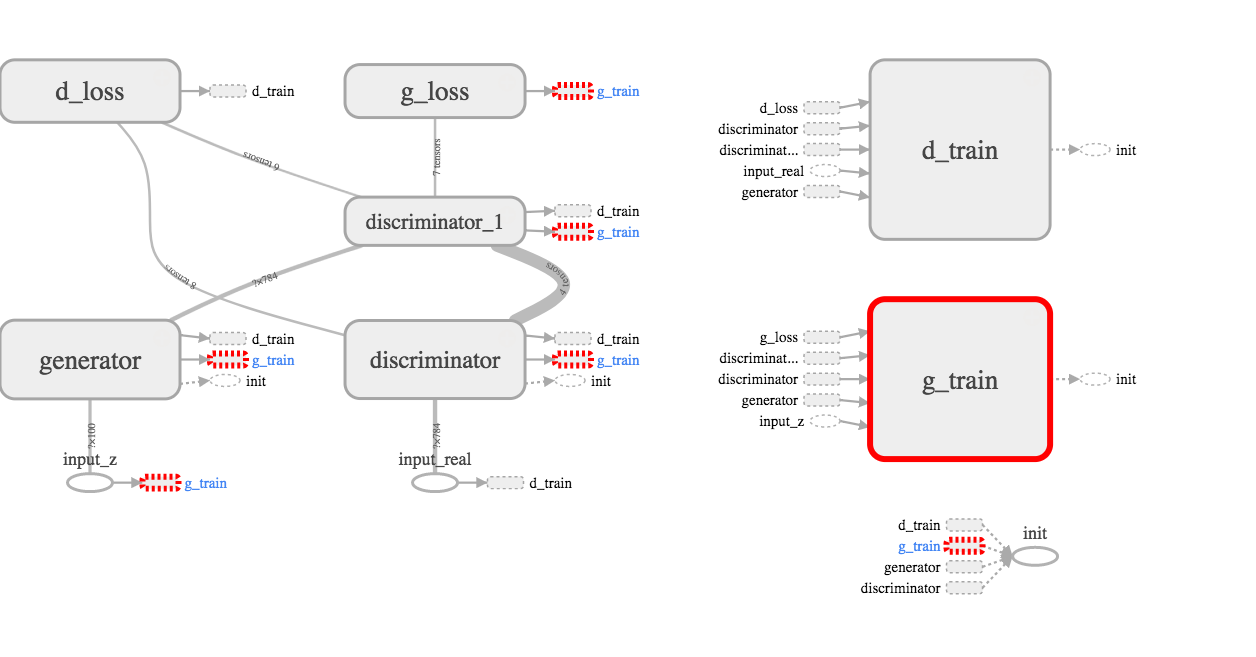
The key point is there are 2 feedback loops. Both give the generator contradicting signal.
minimize(g_loss) is trying to make a fake photo as real as possible, so the output logits will be one. One the other hand, minimize(d_loss) is trying to make fake photo stay fake (logits be 0) and real photo stay real (logits be 1).
Put in another word, g_loss gives 100% feedback to the generator, d_loss gives 50% feedback to generator because only half of the loss is from the generator.
Implementation details can be found at https://github.com/jychstar/NanoDegreeProject/tree/master/DeepND